
Data Identification
Data Identification
Pentaho Data Catalog uses data identification methods called Dictionaries and Data Patterns to help you identify data.
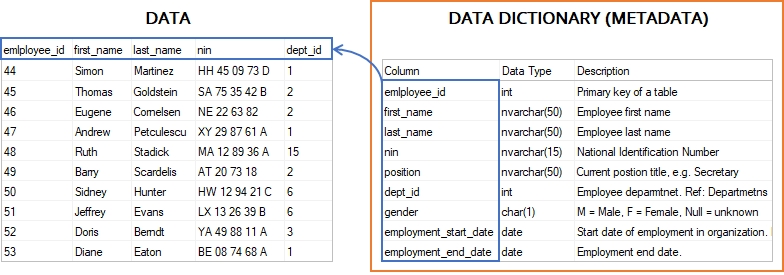
Data Dictionaries in Data Catalogs
A data dictionary in a data catalog is a specialized collection of predefined terms, values, and definitions used to automatically classify and tag data elements within an organization's datasets. Unlike traditional data dictionaries that simply define terminology, catalog data dictionaries function as intelligent matching tools that scan actual data content to identify and categorize information.
These dictionaries serve as automated reference systems that help data catalogs recognize specific types of data by comparing column values against predefined lists of known terms. For example, a country codes dictionary might contain "US," "CA," "GB" to automatically identify geography-related columns, while a product name dictionary could contain specific product identifiers to classify commercial data.
How Data Dictionaries Enable Data Discovery
Data dictionaries in catalogs primarily support column data matching - the process of automatically identifying what type of information a data column contains based on its actual values rather than just column names or metadata. This is particularly valuable for data elements that can't be identified through pattern matching alone, such as:
Country or state codes
Product names or SKUs
Department codes
Custom business terminology
Industry-specific classifications
Types of Data Dictionaries
Modern data catalogs typically support two categories of dictionaries:
System-Defined Dictionaries: Built-in collections that come pre-configured with the catalog, containing common data types like ISO country codes, currency symbols, or standard industry classifications.
User-Defined Dictionaries: Custom collections created by organizations to match their specific business context and terminology. These can be created through multiple approaches:
Importing structured files (CSV with JSON definitions)
Building dictionaries through the user interface
Extracting dictionary terms directly from existing profiled data columns
Benefits for Data Management
By implementing data dictionaries, organizations can achieve:
Automated Data Classification: Systematic identification of data types without manual tagging
Improved Data Discovery: Users can find relevant datasets by searching for business terms rather than technical column names
Consistency Across Systems: Standardized identification of similar data elements across different databases and applications
Enhanced Data Governance: Better understanding of what data exists and where it's located
This automated approach transforms data catalogs from passive repositories into active discovery tools that understand the semantic meaning of organizational data.
Log into Data Catalog:
Username: [email protected]
Password: Welcome123!
View - System Dictionary
Pentaho Data Catalog ships with 95 In-built Dictionaries, pre-configured with common data types like ISO country codes, currency symbols, or standard industry classifications.
We're going to take a look at: Marital_Status
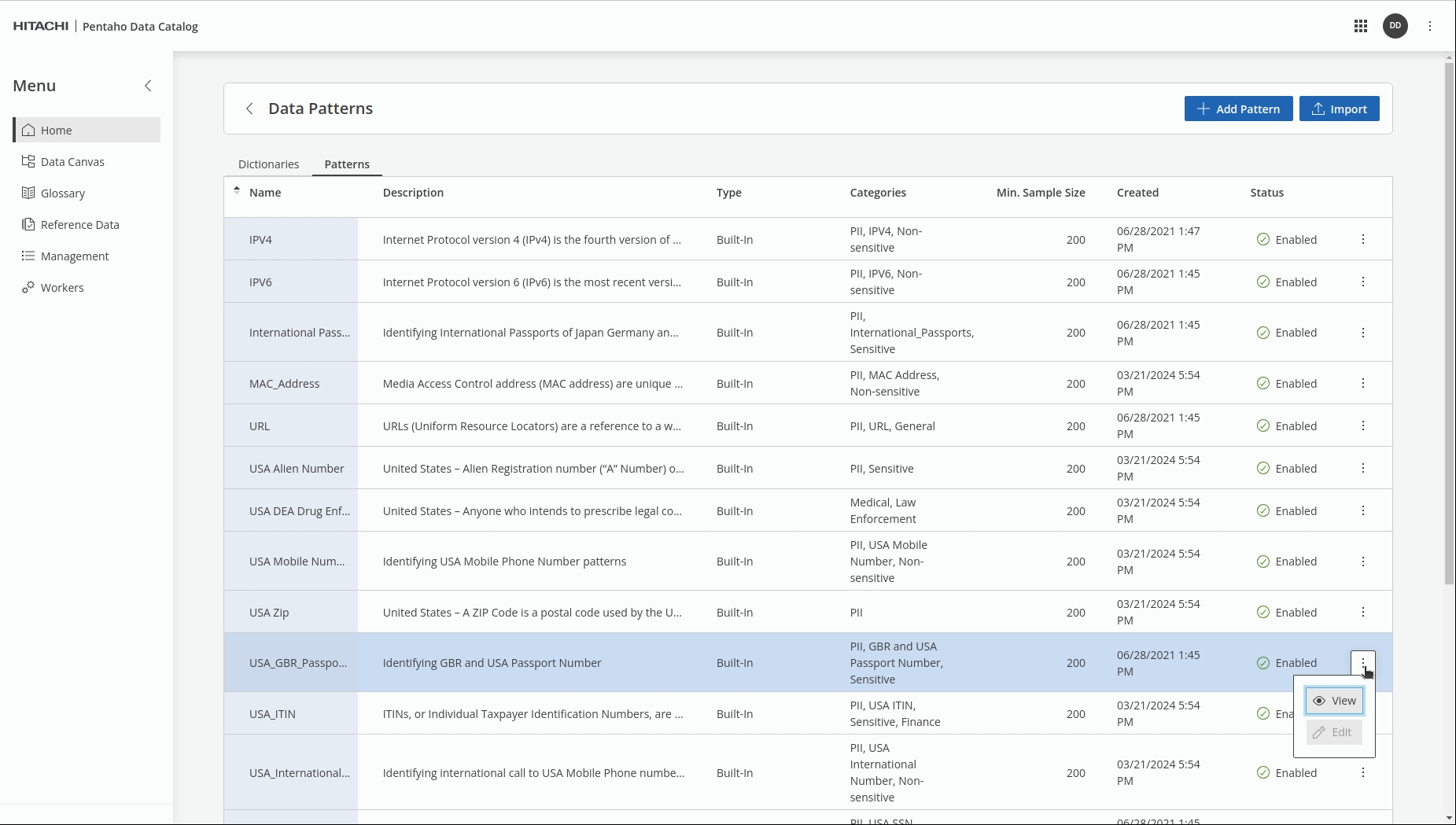
Click: Data Operations > Data Identification Methods.

Click on Dictionaries.

Click on the Name to sort A - Z.

Scroll to Page ⅘
Click on the 3 dots for Marital_Status > View


Click on Rules
[
{
"type": "Dictionary",
"minSamples": 200,
"confidenceScore": {
"+": [
{
"*": [
{
"var": "similarity"
},
0.9
]
},
{
"*": [
{
"var": "metadataScore"
},
0.1
]
}
]
},
"condition": {
"and": [
{
">=": [
{
"var": "confidenceScore"
},
"0.7"
]
},
{
">=": [
{
"var": "columnCardinality"
},
"3"
]
}
]
},
"actions": [
{
"applyTags": [
{
"name": "PII"
},
{
"name": "Sensitive",
"value": "Marital Status",
"t": "sdd;"
}
]
}
]
}
]



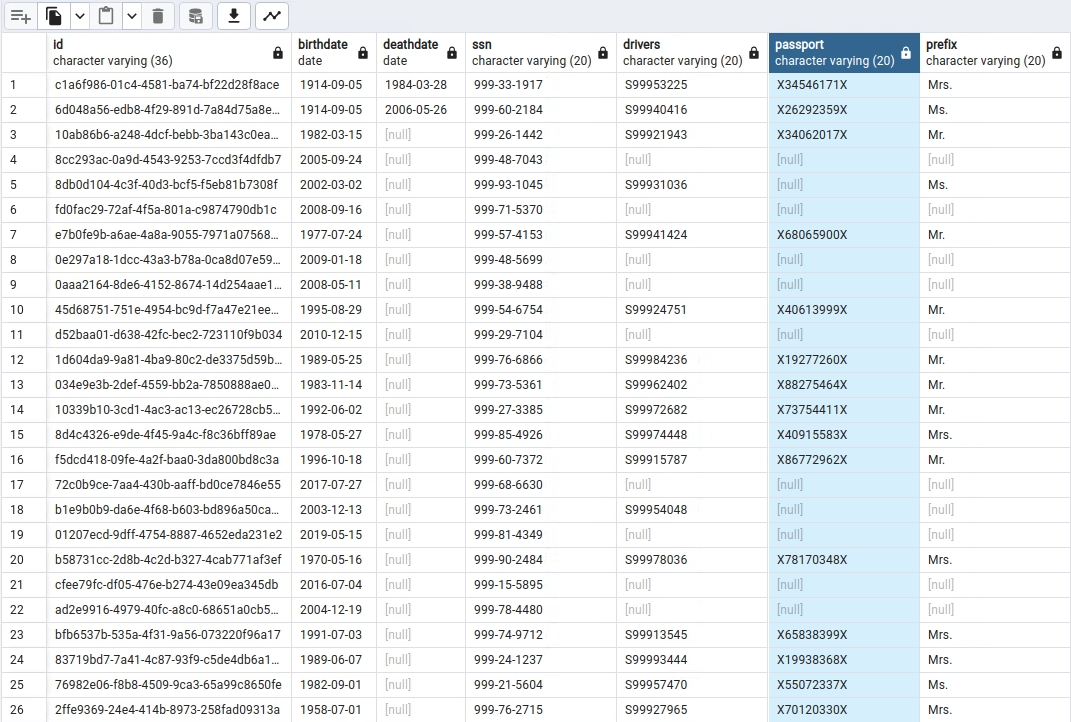
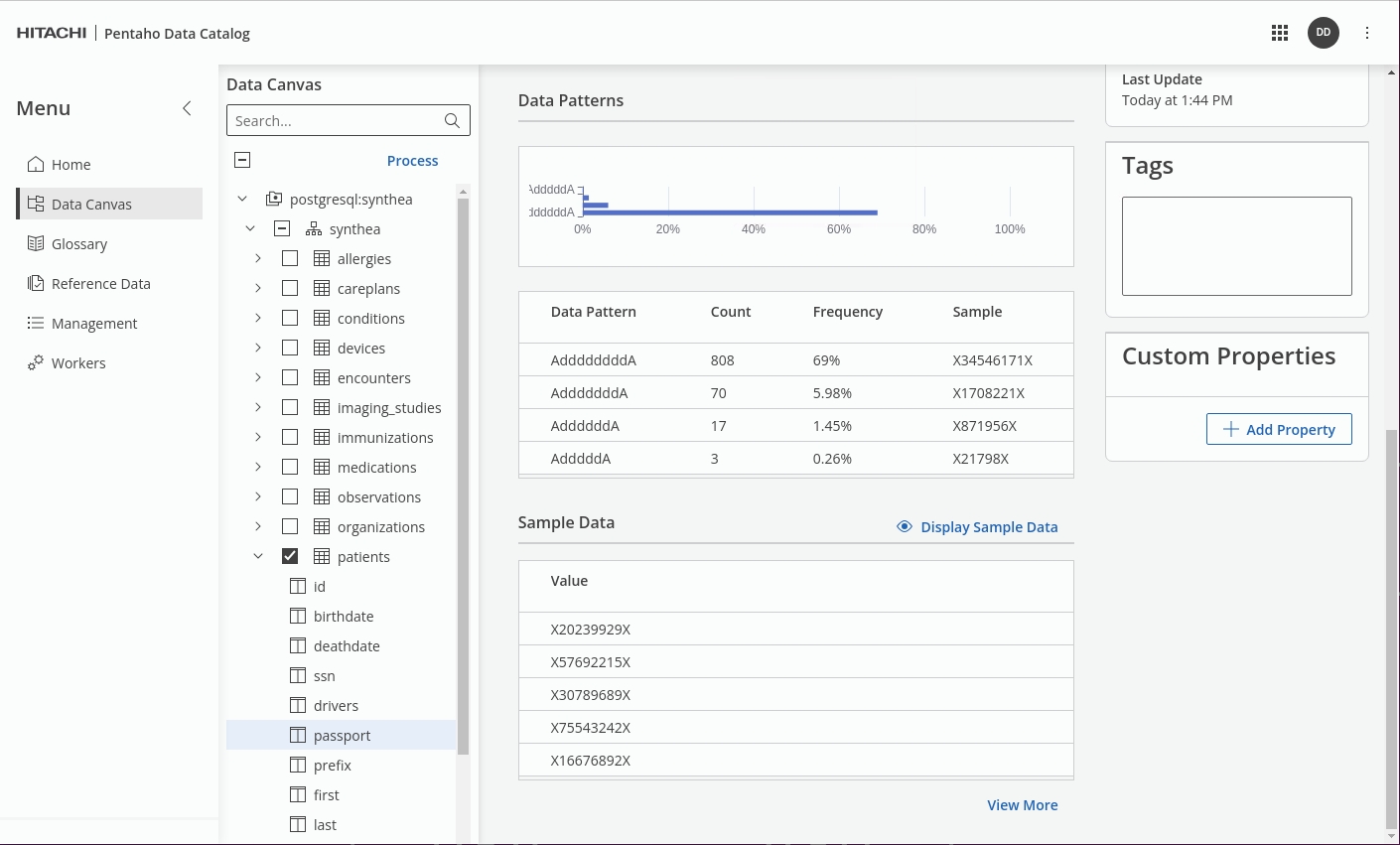
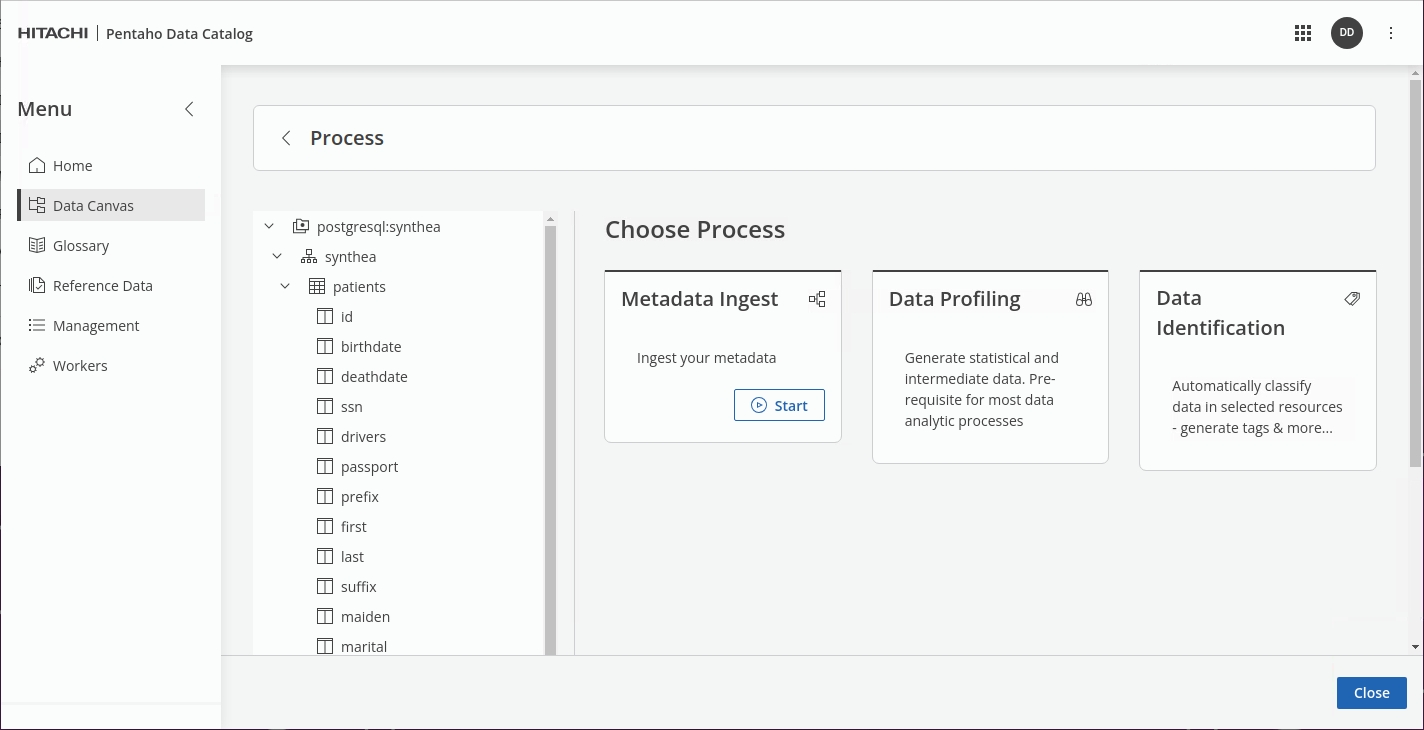
If data profiling is not done, Data Catalog highlights as 'Required'.
Click the Data Identification tile.
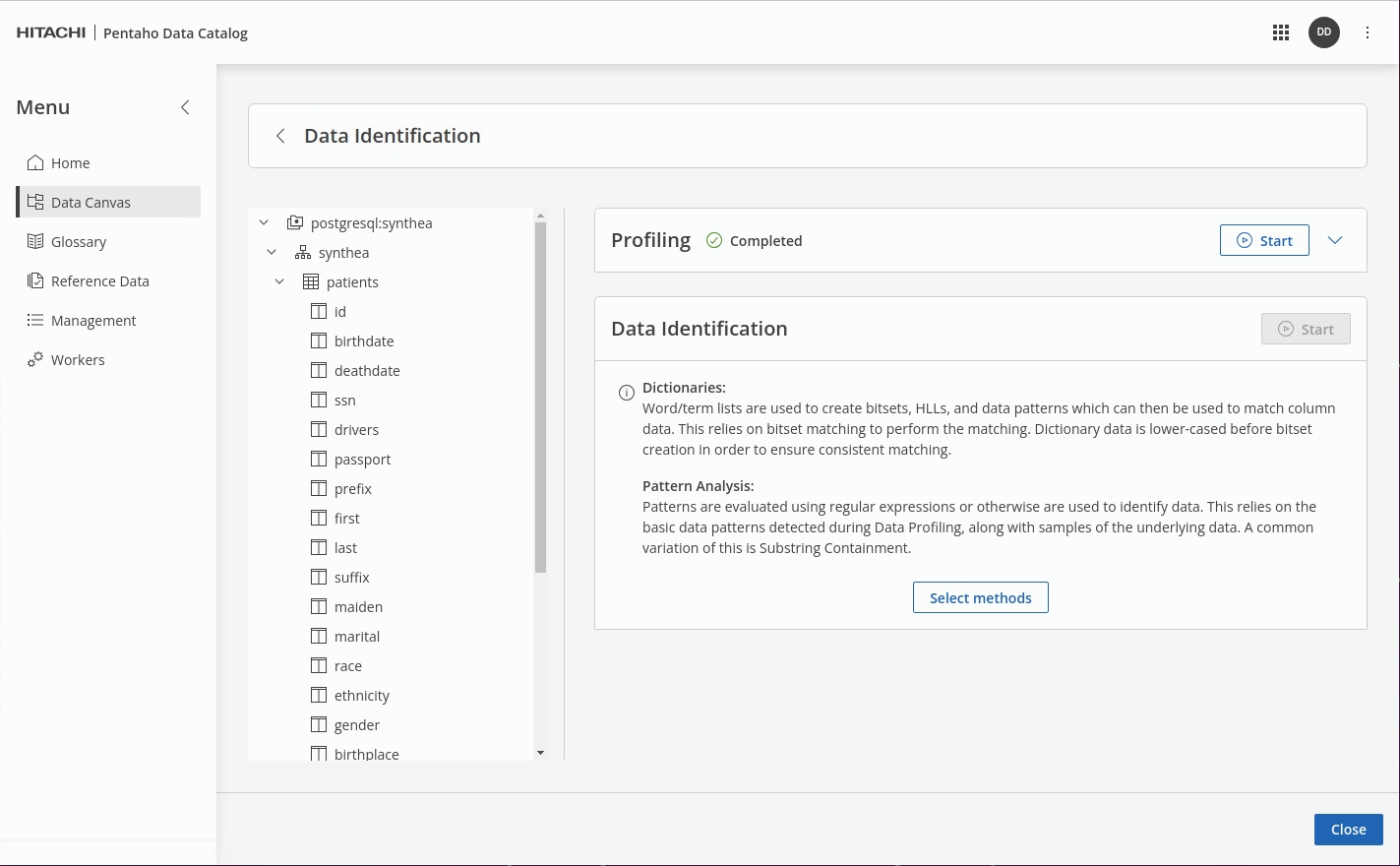
Click 'Select Methods'.
Select the following Data Dictionaries & Data Patterns:
USA_SSN
Social Security Number
Country Codes
Country Names
Country Names
Country Names
DoB
Date of Birth
USA States
States in USA
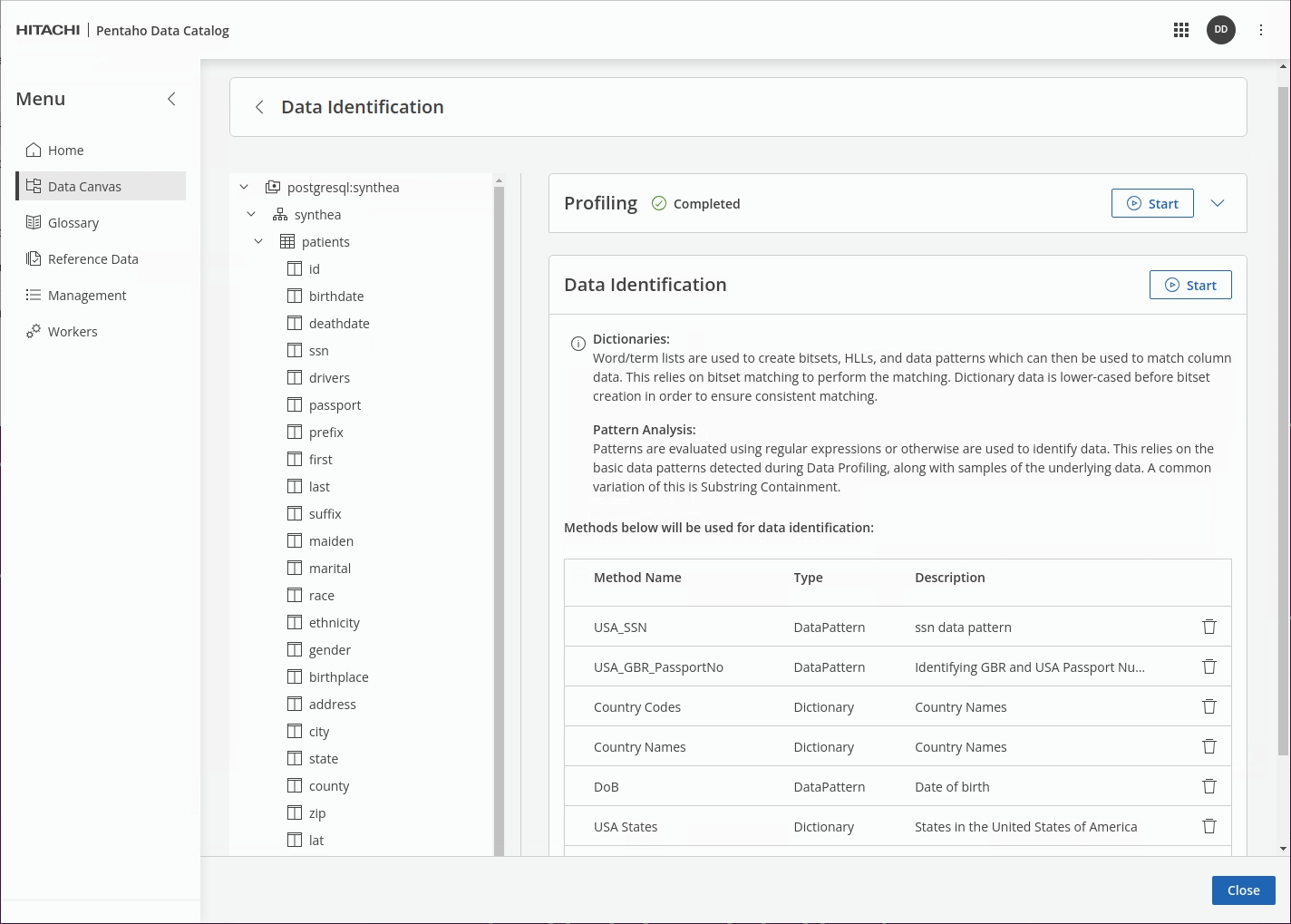
Click Start.
Track the Job in the Workers.
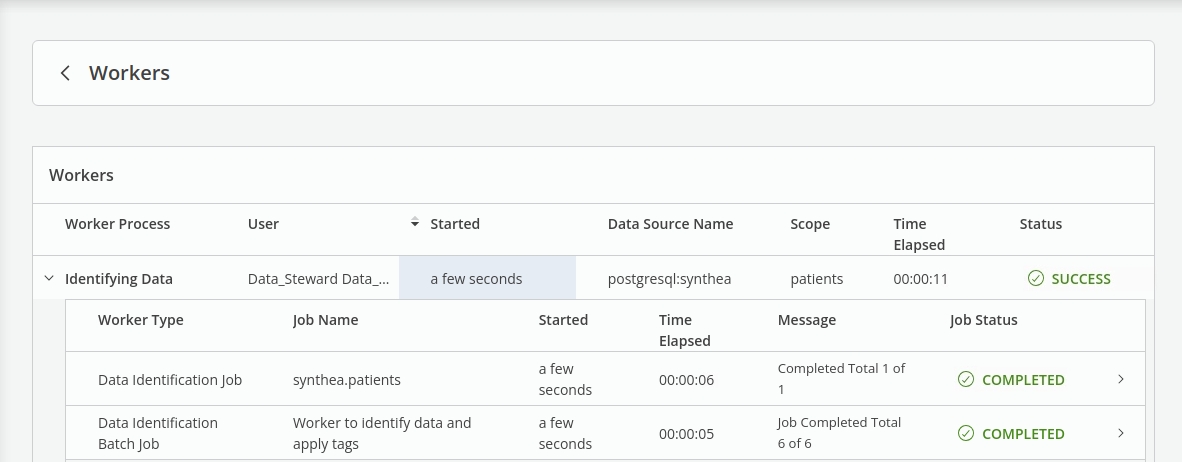
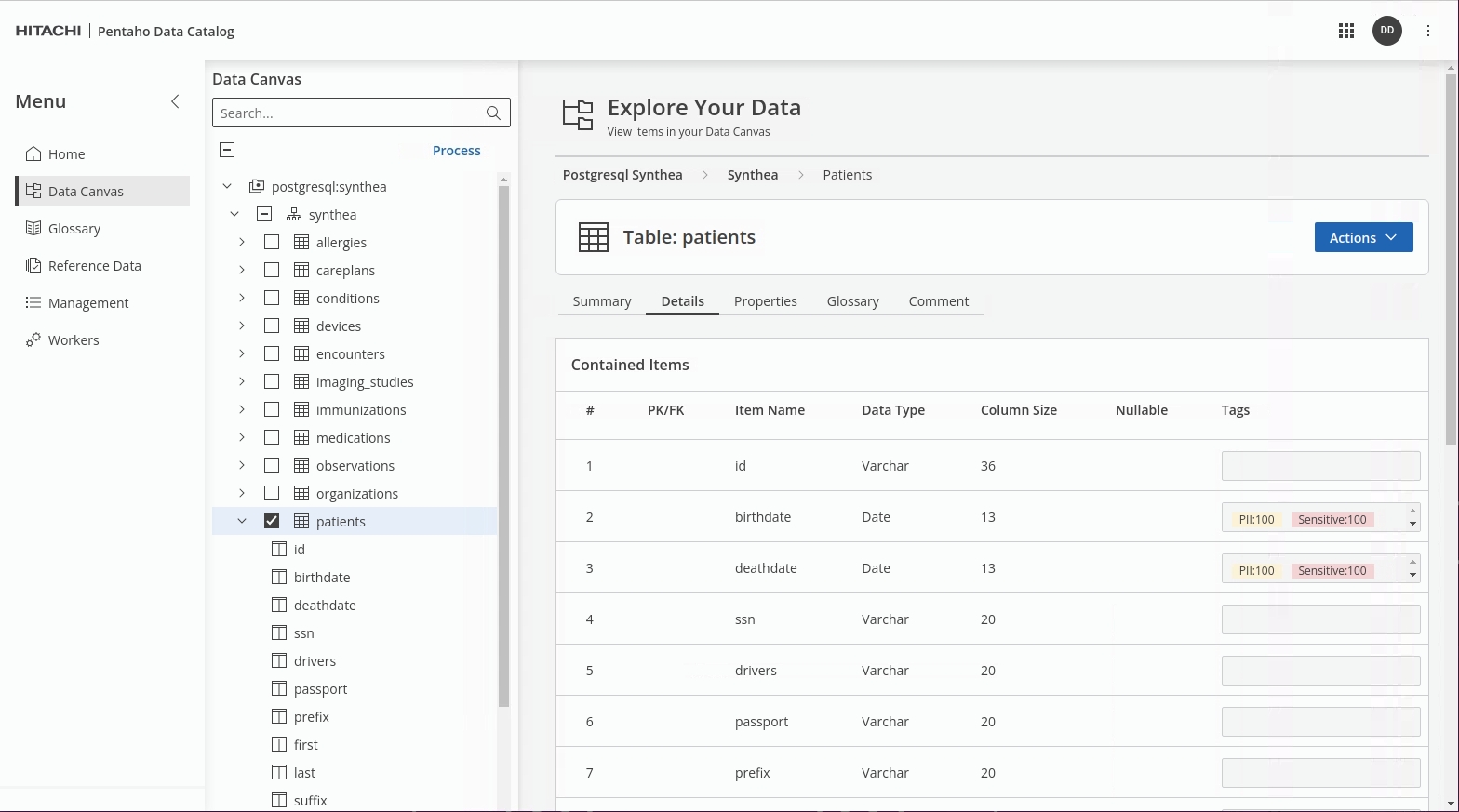
In Data Canvas, check that the sensitive data in the Synthea -> 'patients' table has now been identified - tagged as PII & Sensitive.
x
x
Last updated
Was this helpful?