Kafka EE plugin
Kafka EE plugin

Setup
| Property | Description | Value |
|---|---|---|
| Transformation | Child transformation to process the records | ${Internal.Entry.Current.Directory}/users-to-db-child.ktr |
| Setup | ||
| Connection | Direct: Specify Bootstrap servers. Cluster: Specify a Hadoop cluster configuration. | localhost:9092 |
| Topics | Kafka topics to consume from | pdi-users |
| Consumer Group | Each Kafka consumer step starts a single thread. When part of a consumer group, each consumer is assigned a subset of topic partitions. | pdi-warehouse-users |
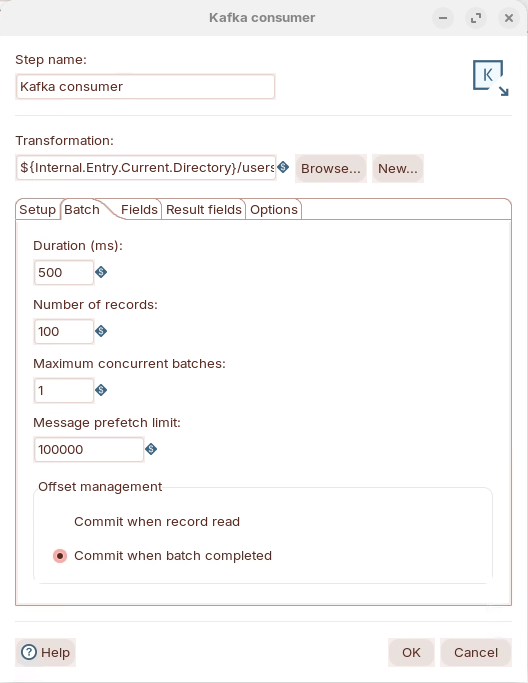
Batch
| Property | Description | Value |
|---|---|---|
| Duration (ms) | Time (in milliseconds) to collect records before executing the child transformation. | 500 |
| Number of records | Number of records to collect before executing the child transformation. | 100 |
| Maximum concurrent batches | Maximum number of batches to collect at the same time. | 1 |
| Message prefetch limit | Limit for incoming messages to queue for processing. | 100000 |
| Offset Management |
| Commit when batch completed |
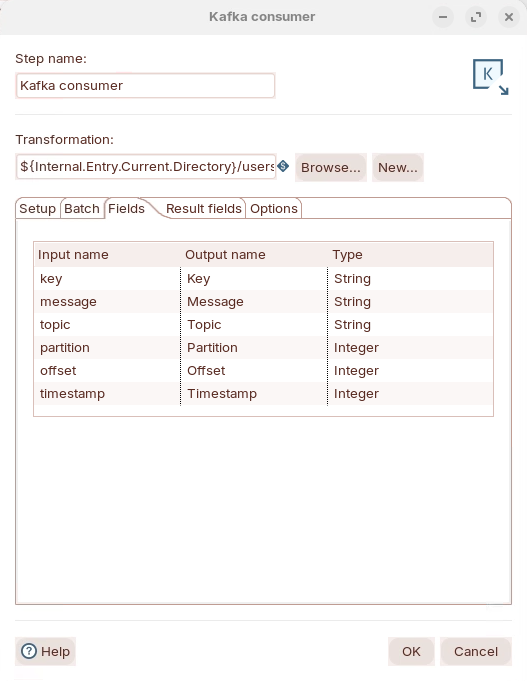
Fields
| Property | Description | Value |
|---|---|---|
| Input Name | Incoming fields received from Kafka streams. Default inputs include: |
|
| Output Name | Output field name. | |
| Type | Data Type |

Results fields
| Property | Description | Value |
|---|---|---|
| Return fields from | Step name in the child transformation that returns fields to the parent transformation. |
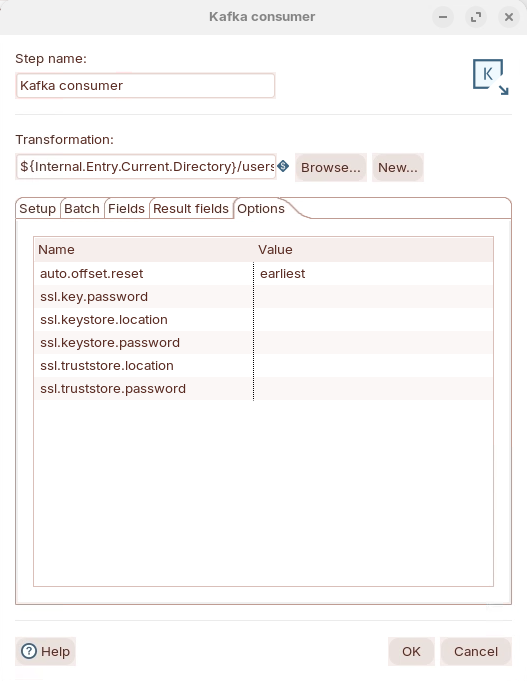
Options
| Property | Description | Value |
|---|---|---|
| auto.offset.reset | set the offset from when to process the records: latest, earliest | earliest |

users-to-db-child.ktr
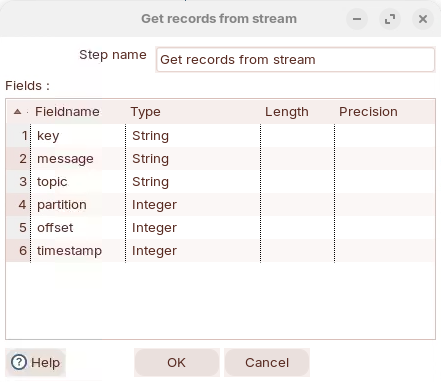
Stream feilds
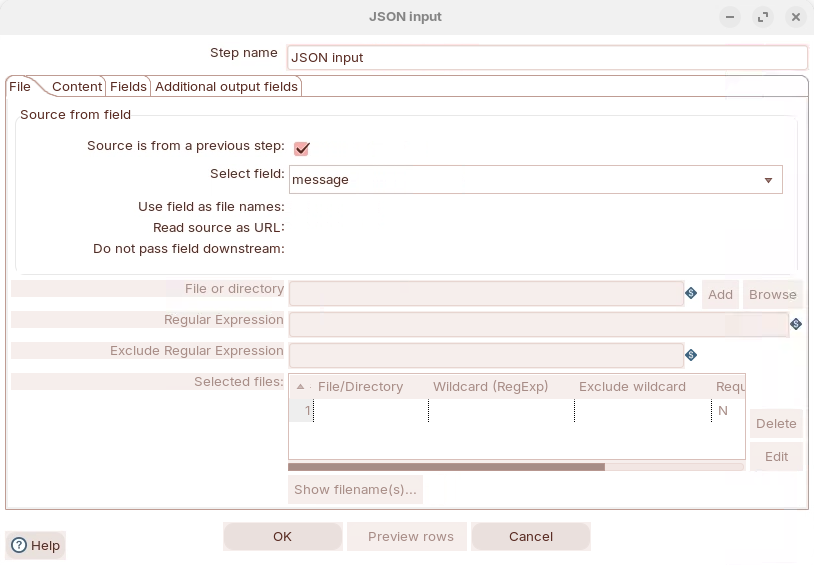
Content
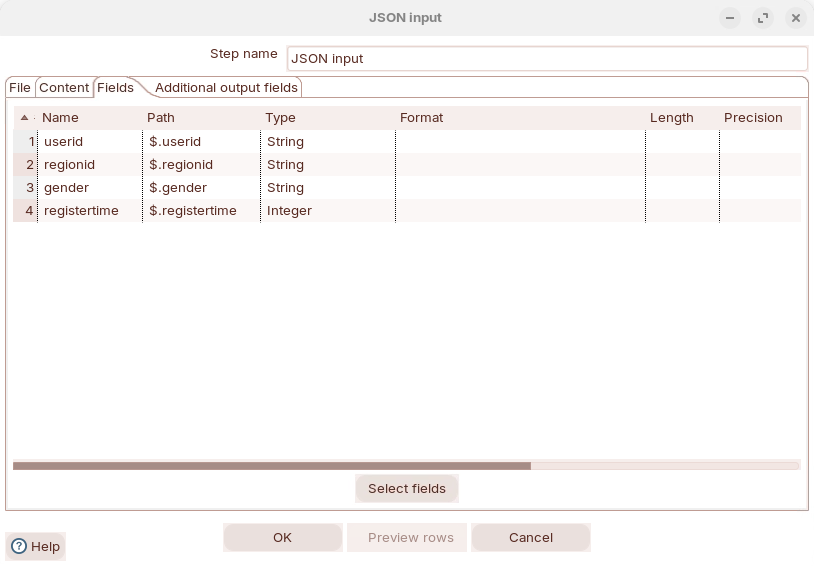
Enter path to retrieve fields
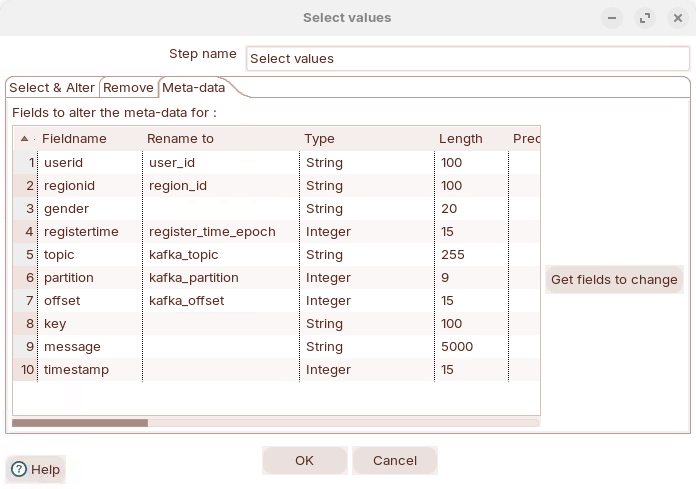
Define Metadata
| Fieldname | Type | Length |
|---|---|---|
user_id | String | 100 |
region_id | String | 100 |
gender | String | 20 |
register_time_epoch | Integer | 15 |
kafka_topic | String | 255 |
kafka_partition | Integer | 9 |
kafka_offset | Integer | 15 |
key | String | 100 |
message | String | 5000 |
timestamp | Integer | 15 |

Formula
| New field | Formula | Value type | Length | Precision | Replace |
|---|---|---|---|---|---|
register_time_seconds | [register_time_epoch] / 1000 | Integer | -1 | -1 | (blank) |
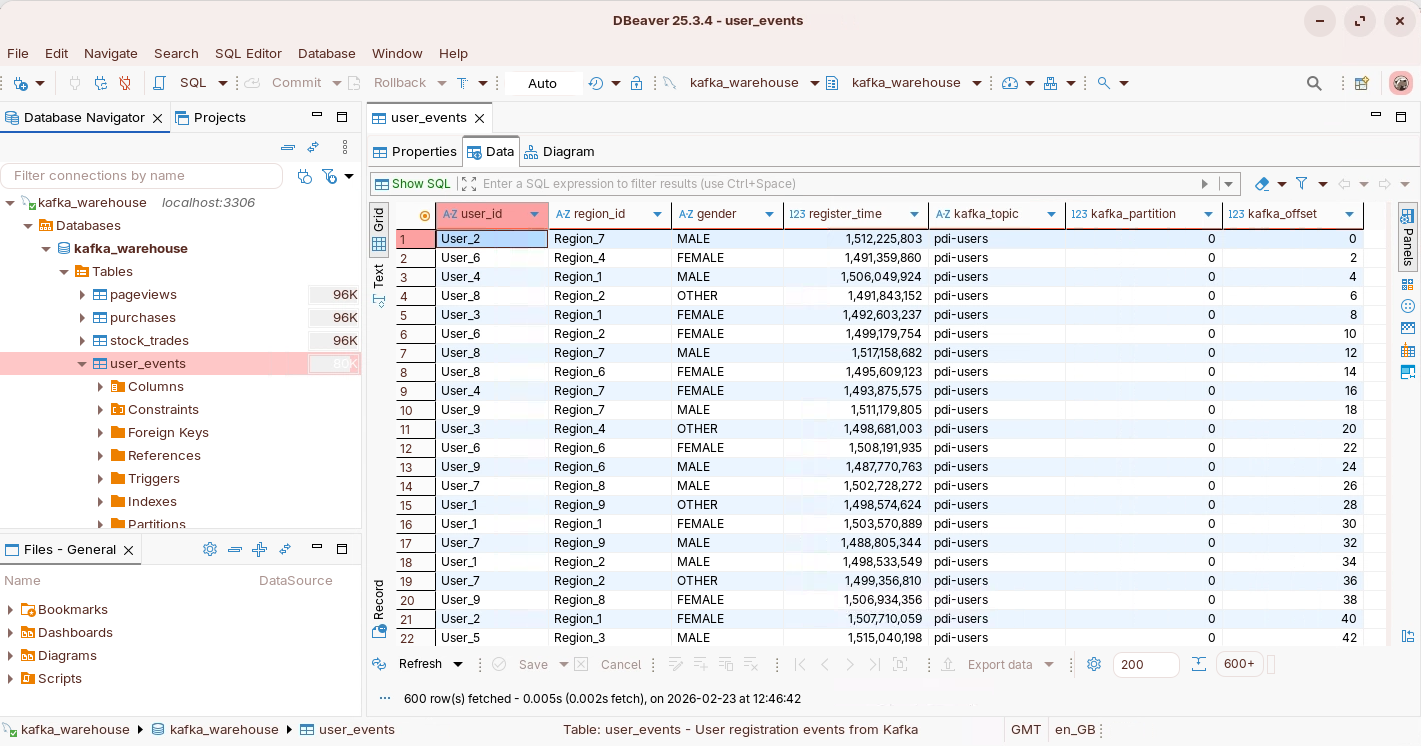
View data - DBeaver